Dify是什么¶
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service) 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
1.大模型接入¶
在 Dify 中,我们按模型的使用场景将模型分为以下3类:
- 系统推理模型。 在创建的应用中,用的是该类型的模型。智聊、对话名称生成、下一步问题建议用的也是推理模型。
- Embedding 模型。在知识库中,将分段过的文档做 Embedding 用的是该类型的模型。在使用了知识库的应用中,将用户的提问做 Embedding 处理也是用的该类型的模型。
- 语音转文字模型。将对话型应用中,将语音转文字用的是该类型的模型。
在 Dify 的 设置 > 模型供应商 中设置要接入的模型。
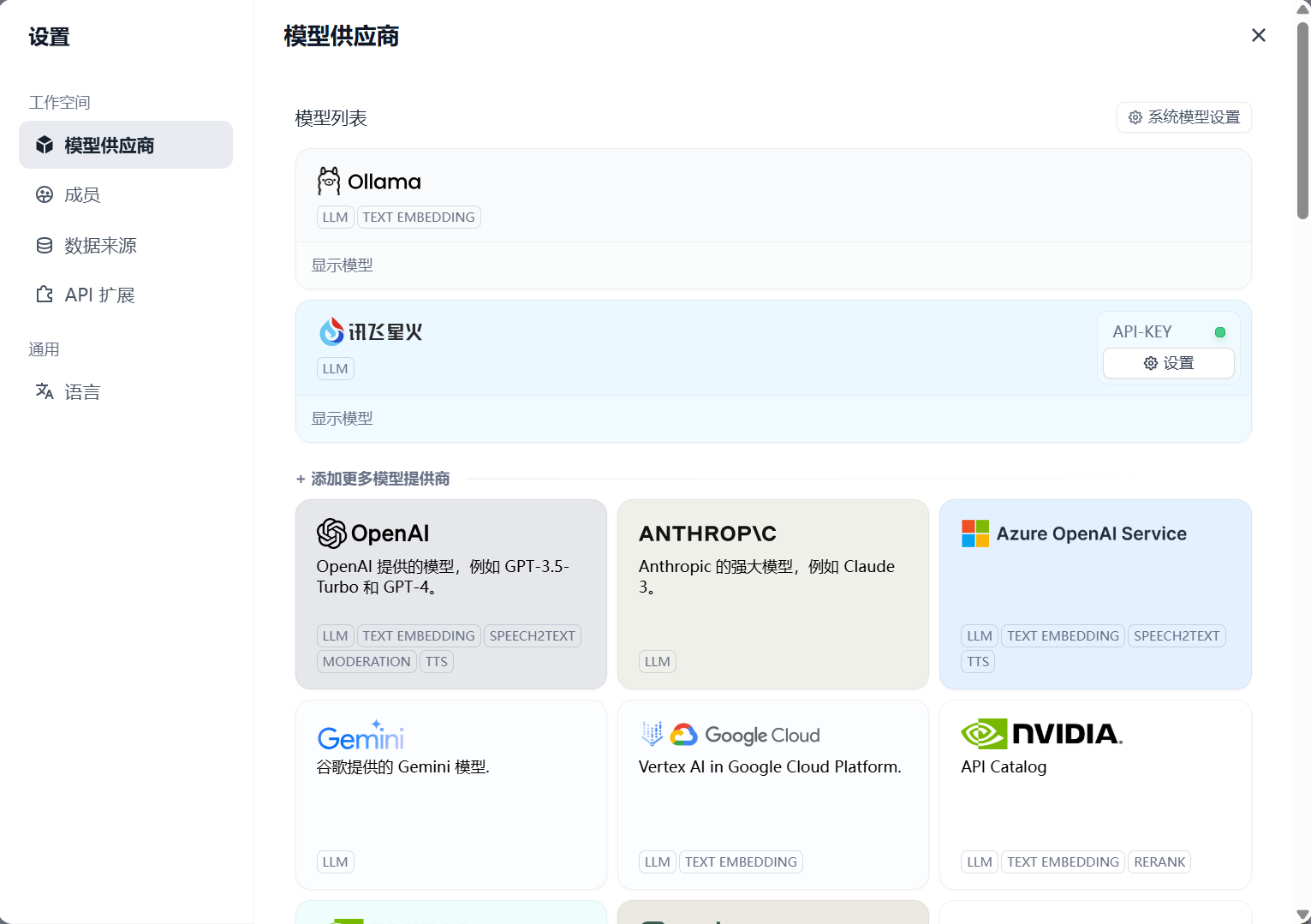
模型使用:

2.应用类型¶
Dify 中提供了五种应用类型:
- 聊天助手:基于 LLM 构建对话式交互的助手
- 文本生成应用:面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
- Agent:能够分解任务、推理思考、调用工具的对话式智能助手
- 对话流:适用于定义等复杂流程的多轮对话场景,具有记忆功能的应用编排方式
- 工作流:适用于自动化、批处理等单轮生成类任务的场景的应用编排方式

3.工作流¶
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
节点是工作流中的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。
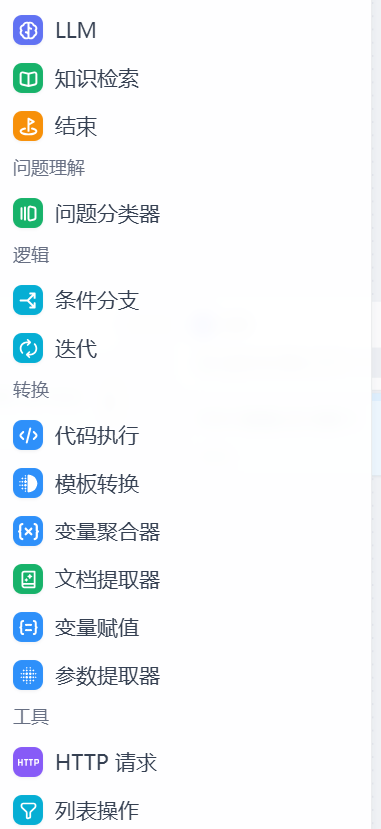
- 开始(Start):定义一个 workflow 流程启动的初始参数。
- 结束(End):定义一个 workflow 流程结束的最终输出内容。
- 大语言模型(LLM):调用大语言模型回答问题或者对自然语言进行处理。
- 知识检索(Knowledge Retrieval):从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文。
- 问题分类(Question Classifier):通过定义分类描述,LLM 能够根据用户输入选择与之相匹配的分类。
- 条件分支(IF/ELSE):允许你根据 if/else 条件将 workflow 拆分成两个分支。
- 代码执行(Code):运行 Python / NodeJS 代码以在工作流程中执行数据转换等自定义逻辑。
- 变量聚合(Variable Aggregator):将多路分支的变量聚合为一个变量,以实现下游节点统一配置。
- 循环(Loop):循环节点用于执行依赖前一轮结果的重复任务,直到满足退出条件或达到最大循环次数。
4. 知识库¶
知识库功能将 RAG 上的各环节可视化,提供了一套简单易用的用户界面来方便应用构建者管理个人或者团队的知识库,并能够快速集成至 AI 应用中。
开发者可以将企业内部文档、规范信息等内容上传至知识库进行结构化处理,供后续 LLM 查询。
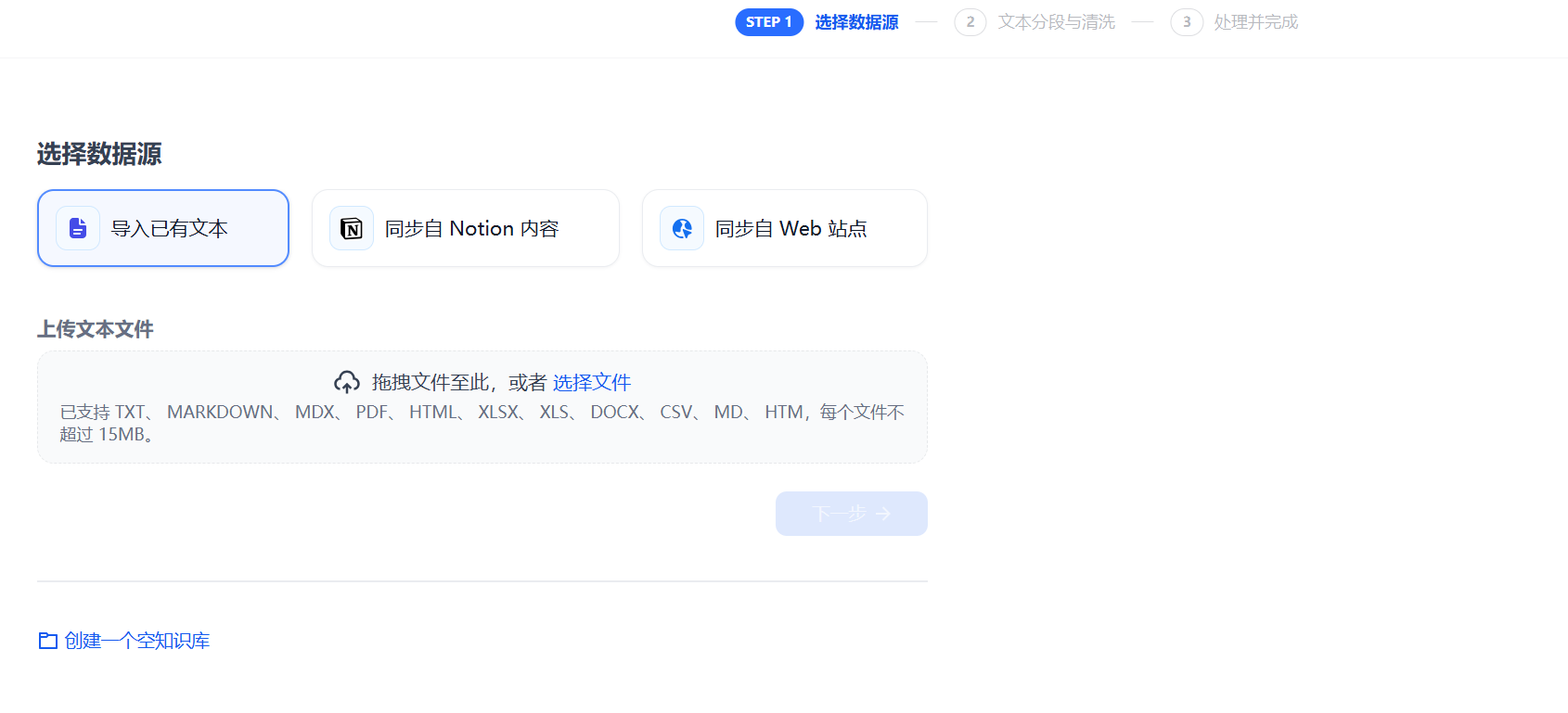
- 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
- 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
- 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
- 完成上传,在应用内关联知识库并使用
5.dify的安装¶
在安装 Dify 之前,请确保您的机器满足以下最低系统要求:
- CPU >= 2 Core
- RAM >= 4 GiB
5.1 安装 WSL(Windows Subsystem for Linux)¶
参考learn.microsoft.com/zh-cn/windo…
- 启用 WSL 打开具有管理员权限的 PowerShell,运行以下命令以安装 WSL:
wsl --install
安装完成后,重启电脑以完成配置。
- 选择 Linux 发行版
如果直接运行
wsl.exe --install -d ubuntu报错,可以通过 Microsoft Store 搜索 "Linux" 并选择合适的 Ubuntu 版本进行安装。安装完成后,系统会提示你设置用户名和密码。
5.2 安装 Docker Desktop¶
- 下载 Docker Desktop 前往 Docker 官方文档 下载适用于 Windows 的 Docker Desktop。
- 安装并配置 Docker 根据安装向导完成 Docker 的安装,并确保启用了 WSL 2 后端支持。这将允许 Docker 在 WSL 环境中无缝运行。
5.3 安装dify环境¶
1. 下载dify项目压缩包¶
可以克隆也可以直接下载
2、进入项目根目录找到docker文件夹¶
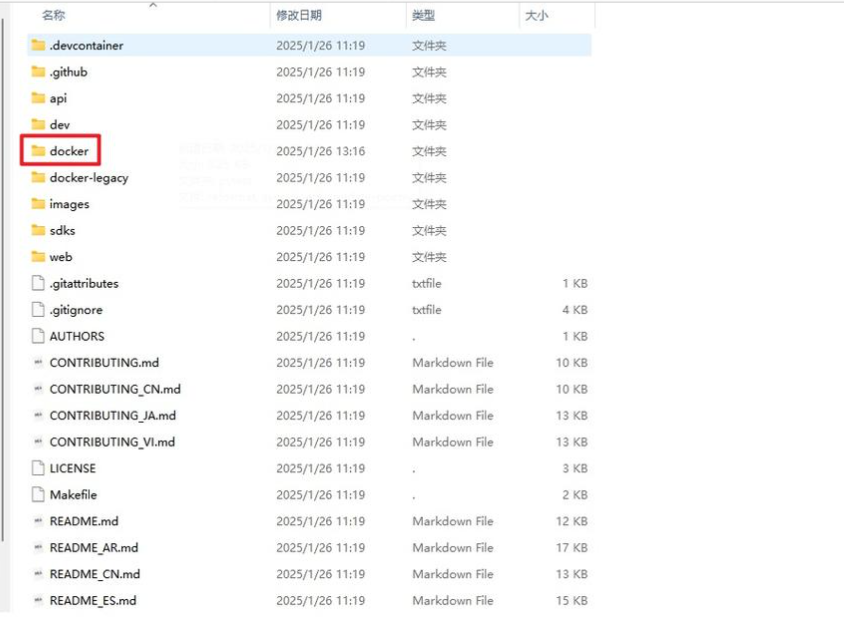
3、.env文件重命名¶

4、右键打开命令行¶
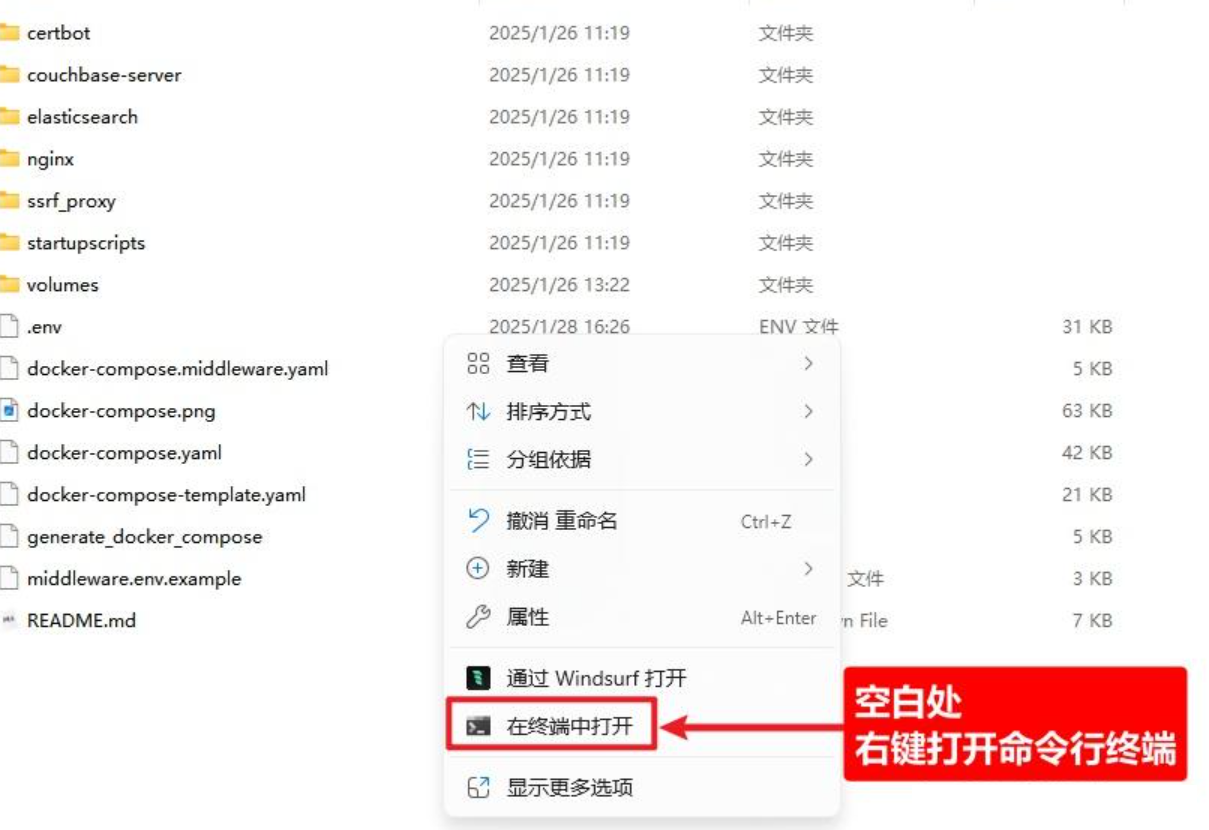
5、运行docker环境¶
docker compose up -d

5.4 启动dify¶
在浏览器地址栏输入即可安装:
http://127.0.0.1/install
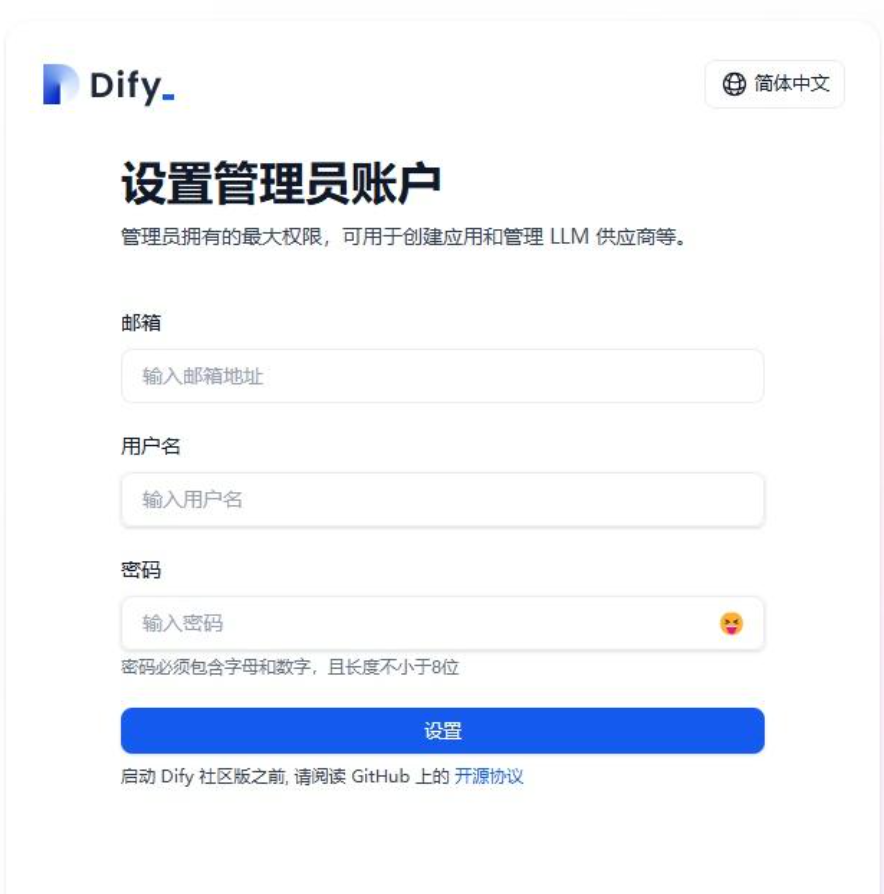
首次登录需进行注册:
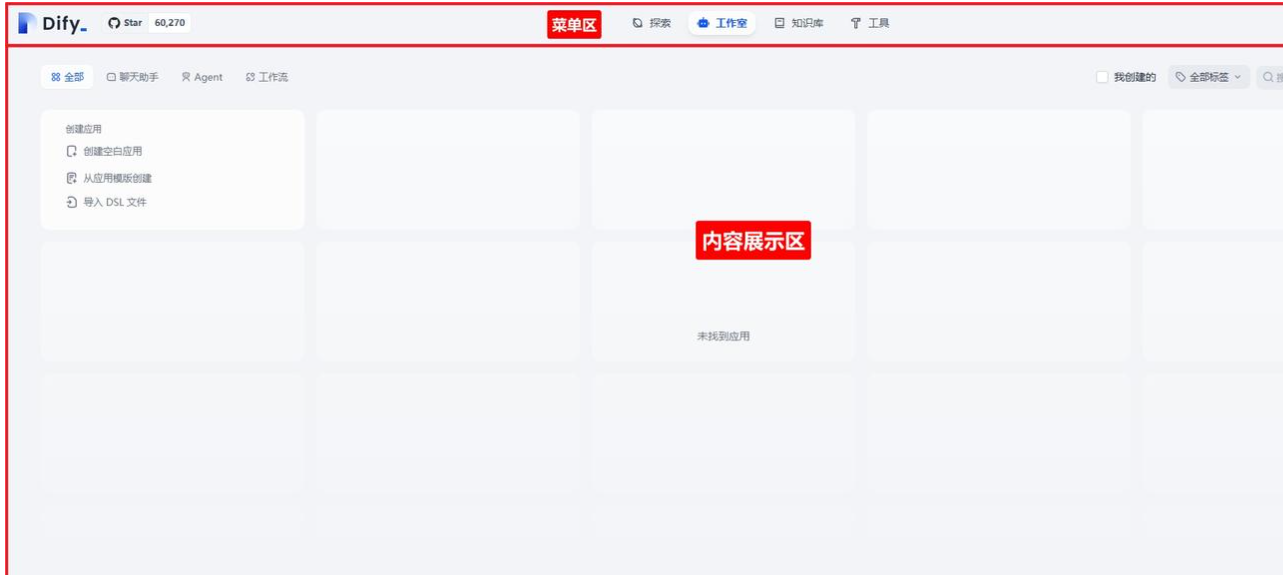
dify的主界面如下所示:
6.docker介绍【扩展】¶
6.1. Docker介绍¶
1.1 什么是虚拟化¶
在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种实体资源,如:服务器、网络、内存、存储等等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍,使用户可以比原来的组态更好的方式来应用这些资源,这些资源的核心虚拟部分是不受现有资源的架设方式,低于或者物理组态所限制,一般所指的虚拟化资源包括计算能力和资料存储。
在实际的生产过程中,虚拟化技术主要是用来解决高性能的物理硬件产能过剩和老的硬件产能过低的重用重组,透明化底层物理硬件,从而最大化的利用物理硬件,对资源充分利用
虚拟化技术种类很多,例如:软件虚拟化、硬件虚拟化、内存虚拟化、网络虚拟化(vip),桌面虚拟化、服务虚拟化、虚拟机等等。
虚拟化简单讲,就是把一台物理计算机虚拟成多台逻辑计算机,每个逻辑计算机里面可以运行不同的操作系统,相互不受影响,这样就可以充分利用硬件资源
1.2 初识Docker¶

l Docker是一个开源的**应用容器引擎**
l 诞生于2013年初,基于Go语言实现,dotCloud公司出品(后改名为Docker Inc)
l Docker可以让开发者打包他们的应用以及依赖包到一个**轻量级,可移植的容器中**,然后发布到任何流行的linux服务器上
l 容器是完全使用沙箱机制,相互隔离

l 容器性能开销极低
Docker是一种容器技术,解决软件跨环境迁移的问题
1.3 容器与虚拟机的比较¶
什么是虚拟机
虚拟机是一个计算机系统的仿真,简单来说,虚拟机可以实现在一台物理计算机上模拟多台计算机运行任务。 操作系统和应用共享一台或多台主机(集群)的硬件资源,每台VM有自己的OS,硬件资源是虚拟化的。管理程序(hypervisor)负责创建和运行VM,它连接了硬件资源和虚拟机,完成server的虚拟化。 由于虚拟化技术和云服务的出现,IT部门通过部署VM可以可减少cost提高效率。
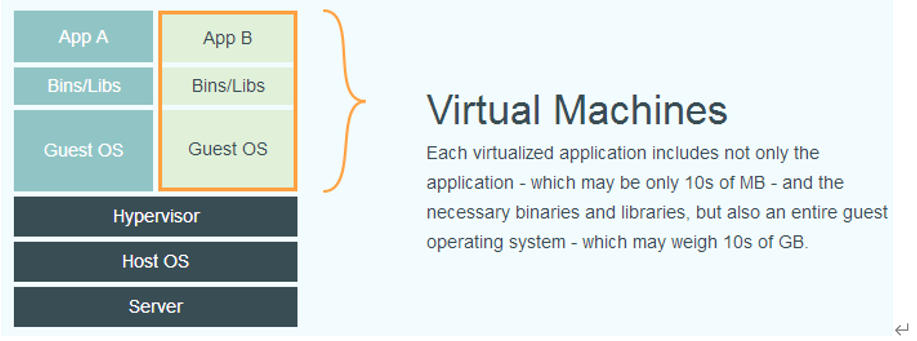
VMs也消耗大量系统资源,每个VM不仅运行一个OS的完整copy并且需要所有硬件的虚拟化copy,这消耗大量RAM和CPU。相比单独计算机,VM是比较经济的,但对于一些应用VM是过度浪费的,需要容器。
什么是容器
容器是将操作系统虚拟化,这与VM虚拟化一个完整的计算机有所不同。 容器是在操作系统之上,每个容器共享OS内核,执行文件和库等。共享的组件是**只读**的,通过共享OS资源能够减少复现OS的代码,意味着一台server仅安装一个OS可以运行多个任务。容器是非常轻量的,仅仅**MB**水平并且几秒即可启动。相比容器,VM需要几分钟启动,并且大小也大很多。 与VM相比,容器仅需OS、支撑程序和库文件便可运行应用,这意味你可以在同一个server上相比VM运行2-3倍多的应用,并且,容器能帮助创建一个可移植的,一致的开发测试部署环境。

小结:
| 特性 | 虚拟机 | 容器 |
|---|---|---|
| 隔离级别 | 操作系统级 | 进程级 |
| 隔离策略 | 运行于Hypervisor上 | 直接运行在宿主机内核中 |
| 系统资源 | 5-15% | 0-5% |
| 启动速度 | 慢,分钟级 | 快,秒级 |
| 占用磁盘空间 | 非常大,GB-TB级 | 小,KB-MB甚至KB级 |
| 并发性 | 一台宿主机十几个,最多几十个 | 上百个,甚至上百上千个 |
| 高可用策略 | 备份、容灾、迁移 | 弹性、负载、动态 |
结论:
与传统的虚拟化相比,Docker优势体现在启动速度快,占用体积小
6.2. Docker与虚拟机的形象比喻¶
2.1 什么是物理机¶

2.2 什么是虚拟机¶

2.3 什么是docker¶

6.3. Docker组件¶
3.1 Docker服务端和客户端¶
Docker****是一个客户端-服务端(C/S)架构程序,Docker客户端只需要向Docker服务端或者守护进程发出请求,服务端或者守护进程完成所有工作返回结果,Docker提供了一个命令行工具Docker以及一整套的**Restful API**,可以在同一台宿主机器上运行Docker守护进程或者客户端,也可以从本地的Docker客户端连接到运行在另一台宿主机上的远程Docker守护进程
docker引擎是一个c/s结构的应用,主要组件见下图:
Docker使用C/S架构,Client 通过接口与Server进程通信实现容器的构建,运行和发布。client和server可以运行在同一台集群,也可以通过跨主机实现远程通信。

3.2 Docker镜像¶
Docker 镜像(Image)就是一个只读的模板。例如:一个镜像可以包含一个**完整的操作系统环境**,里面仅安装了 Apache 或用户需要的其它**应用程序**。镜像可以用来创建 Docker 容器,一个镜像可以创建很多容器。Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直接从其他人那里下载一个已经做好的镜像来直接使用。
镜像(Image)就是一堆只读层(read-only layer)的统一视角,也许这个定义有些难以理解,看看下面这张图:

右边我们看到了多个**只读层**,它们重叠在一起。除了最下面一层,其它层都会有一个指针指向下一层。这些层是Docker内部的实现细节,并且能够在docker宿主机的文件系统上访问到。统一文件系统(Union File System)技术能够将不同的层整合成一个文件系统,为这些层提供了一个统一的视角,这样就隐藏了多层的存在,在用户的角度看来,只存在一个文件系统。
3.3 Docker容器¶
Docker 利用容器(Container)来运行应用。容器是从镜像创建的**运行实例**。它可以被**启动、开始、停止、删除**。每个容器都是相互隔离的、保证安全的平台。
可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
创建Container首先要有Image,也就是说Container是通过image创建的。
Container是在原先的Image之上新加的一层,称作**Container layer**,这一层是可读可写的(Image是只读的)。
在面向对象的编程语言中,有类跟对象的概念。类是抽象的,对象是类的具体实现。Image跟Container可以类比面向对象中的类跟对象,Image就相当于抽象的类,Container就相当于具体实例化的对象。
Image跟Container的职责区别:Image****负责APP的存储和分发,Container负责运行APP。

结论:
容器 = 镜像 + 读写层。并且容器的定义并没有提及是否要运行容器